创新的域自适应方法可从单深度图像进行3D人脸重建
发布时间:2024-03-04 14:44:56来源:
从视觉效果重建3D脸部对于数字脸部建模和操作至关重要。传统方法主要依赖于RGB图像,这些图像容易受到光照变化的影响并且仅提供2D信息。相比之下,深度图像可以抵抗光照变化,直接捕获3D数据,为稳健的重建提供了潜在的解决方案。
最近的研究转向深度学习,以从深度数据中进行更稳健的重建;然而,缺乏具有准确3D面部标签的真实深度图像阻碍了训练过程。由于领域差异,使用自动合成数据进行训练的尝试在推广到现实场景时遇到了限制。
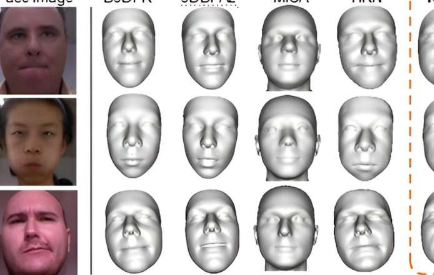
蔡晓旭领导的研究团队于2024年2月15日在《计算机科学前沿》上公布了他们的最新发现。他们的研究引入了一种新颖的领域自适应重建方法,利用深度学习以及自动标记的合成数据和未标记的真实数据的融合。这种方法有助于根据现实世界中捕获的单个深度图像重建3D面部。
他们的方法实现了域自适应神经网络,分别致力于预测头部姿势和面部形状。每个网络都使用针对其组件定制的特定策略进行训练。
头部姿势网络使用简单的微调方法进行训练,而更强大的对抗域适应方法则用于训练面部形状网络。
预处理的初始步骤涉及将深度图像中的像素值转换为相机空间内的3D点坐标。此过程允许在重建网络中利用2D卷积来处理3D几何信息。网络输出采用3D顶点偏移,建立更集中的目标分布以促进学习过程。
该方法在具有挑战性的现实世界数据集上进行了彻底评估,证明了其与最先进技术相比的竞争性能。
免责声明:本答案或内容为用户上传,不代表本网观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。 如遇侵权请及时联系本站删除。