Adaptive-k一种在标签噪声数据集中进行稳健训练的简单有效方法
在大型数据集上训练深度学习模型对于其成功至关重要;然而,这些数据集通常包含标签噪声,这会显著降低测试数据集的分类性能。
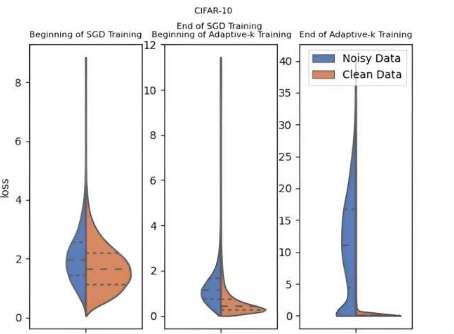
为了解决这个问题,由耶尔德兹技术大学的 Enes Dedeoglu、H. Toprak Kesgin 和 M. Fatih Amasyali 教授组成的研究团队开发了一种名为 Adaptive-k 的方法,该方法改进了优化过程并在存在标签噪声的情况下获得更好的结果。
他们的研究成果发表在《计算机科学前沿》杂志上。
Adaptive-k 方法通过自适应地确定从小批量中选择进行更新的样本数量而脱颖而出,从而更有效地分离噪声样本,并最终提高标签噪声数据集中训练的成功率。
这种创新方法简单、有效,不需要事先了解数据集的噪声比、额外的模型训练或显著增加训练时间。Adaptive-k 已证明其有潜力彻底改变深度学习模型在噪声数据集上的训练方式,其性能最接近 Oracle 方法,其中噪声样本完全从数据集中移除。
在他们的研究中,该团队将 Adaptive-k 方法与其他流行算法(例如 Vanilla、MKL、Vanilla-MKL 和 Trimloss)进行了比较,并评估了其与 Oracle 场景(其中所有噪声样本都是已知并被排除)相关的性能。
在三个图像数据集和四个文本数据集上进行了实验,结果表明 Adaptive-k 在标签噪声数据集上表现始终更佳。此外,Adaptive-k 方法与各种优化器兼容,例如 SGD、SGDM 和 Adam。
演示了 Adaptive-k 如何在 MNIST 数据集的自适应训练期间准确估算干净样本比率。图片来源:Enes Dedeoglu、Himmet Toprak Kesgin、Mehmet Fatih Amasyali
本研究的主要贡献包括:
介绍 Adaptive-k,一种用于标签噪声数据集的稳健训练的新算法,该算法易于实现并且不需要额外的模型训练或数据增强。
Adaptive-k 的理论分析以及与 MKL 算法和 SGD 的比较。• 使用 Adaptive-k 进行高精度噪声比估计,无需事先了解数据集或超参数调整。
在多个图像和文本数据集上对 Adaptive-k 与 Oracle、Vanilla、MKL、Vanilla-MKL 和 Trimloss 算法进行实证比较。
未来的研究将集中于改进 Adaptive-k 方法,探索更多应用,并进一步提高其性能。
免责声明:本答案或内容为用户上传,不代表本网观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。 如遇侵权请及时联系本站删除。